
Введение
Данный пост является переводом вот этой статьи, снабженный моими коментариями.
Без введения никуда — во первых, контекст, во вторых — дань уважения автору. так что — введение! Далее по тексту — мои прямые (не скрытые в вольностях перевода) комментарии будут выделены курсивом.
Итак, у нас есть официальный бестпрактис по докеру от самих разработчиков докера
Однако, он концентрируется на глубоко технических вещах, таких как правильны структура Docker файла, нежели практики применения технологии в целом. Так скажем любой новичок в Docker очень быстро придет к базовому пониманию использования слоев, как они кешируются и как создать небольшой образ. Такие вещи как multi-stage builds в Docker тоже не то чтобы сильно сложные (если потребуется- вы разберетесь), ну а сам синтаксис Docker files в целом не сложен для понимания.
Самое интересное заключается в порой неспособности компаний иначе взглянуть на используемые ими технологии, представить картину в целом и особенно учесть такие нюансы контейнеризации как иммутабельность контейнера или образа. Можно сказать (тут я не могу привести пример и целиком доверяю автору) что компании порой пытаются перенести их процессы и практики, построенные для инфраструктуры, основанной на технологиях виртуализации и использовании виртуальных машин на контейнеры… И естественно получают такие себе результаты. Все от того что вокруг нас много низкоуровневой технической информации о том, как устроены контейнеры, но недостаточно высокоуровневого представления об их эксплуатации (тут я никак не могу подтвердить или опровергнуть мнение автора, но по моему опыту таких “отбитых” все же мало, но может я просто везучий).
Цель этой статьи — предоставить высокоуровневые хорошие практики по Docker. Так как все случаи в жизни не покрыть, идти будем от обратного (как во “Вредных советах”) и на примере плохих практик — то есть как делать не надо и почему. Разберем 10 плохих практик:
- Попытка использовать контейнеры как виртуальные машины.
- Создание запутанных Docker файлов.
- Создание Dockerfiles, которые могут как-то влиять на внешнюю среду.
- Смешивать образы, используемые для развертывания, с образами, используемыми для разработки.
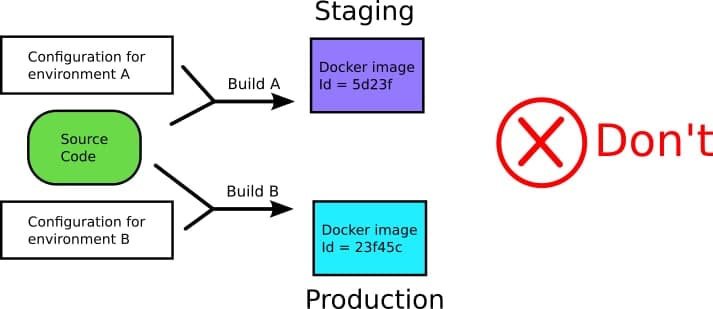
- Создание различных образов для каждой среды (dev, stage, prod).
- Вытягивание кода из git на prod серверы и создание образов на лету.
- Продвижение git-хэшей между командами.
- Жесткое встраивание секретов в образы контейнеров.
- Использование Docker в качестве CI/CD для бедных (так себе название пункта, я знаю, но тема там дальше раскроется).
- Предположение о том что докер — это просто еще один способ упаковки
Антипаттерн номер один
Docker контейнеры это не виртуальные машины!
Так, тут автор приводит небольшую справку — раз у нас перевод, я не могу пройти мимо и не повторить за ним, уж простите….
Прежде чем нырять в какие то практические вещи, давайте немного уделим внимания базовой теории. Контейнеры это не Виртуальные Машины. На первый взгляд они конечно могут походить на них, но истина в том что это абсолютно иное явление.
Если прошерстить наш любимый stackoverflow, можно наткнуться на такие замечательные вопросы как:
- Как мне обновить приложение, запущенное внутри контейнера?
- Как мне попасть внутрь Docker контейнера по SSH?
- Как мне вытащить файлы/логи из контейнера?
- Как мне применить некое исправление безопасности внутри контейнера?
- Как мне запустить несколько программ в контейнере?
Все эти вопросы технически корректные (ну то есть формулировка вопроса не содержит полную ересь), а люди, отвечающие на эти вопросы так же предоставляют технически верные ответы. Однако все эти вопросы являются каноническим представлением проблемы XY (вот за что люблю переводить чужие статьи- узнаю вот такие вещи. Ведь когда читаешь часто пропускаешь. А тут полез читать что это за XY проблема. Чтобы сейчас не прерываться, я сделаю отдельную сноску об этом).
Как мне забыть (все чему учили в школе?) все мои практики, связанные с VM и изменить мой рабочий процесс на то, чтобы работать с иммутабельными, короткоживущими, stateless (да, этот термин лучше использовать как есть, имхо — короче не имеющими сохраняемого на диск состояния, работающими в формате запрос-ответ-забыли) контейнерами вместо изменяемых, долгоживущих, statefull (аналогично — сохраняющими состояние) виртуальных машин?
Ряд компаний (серьезно — кто эти люди? Пожалуйста, подскажите в комментах, мне правда интересно) пытаются переиспользовать те же практики/инструменты/навыки, которые применяли для виртуальных машин в мире контейнеров. Некоторые из них даже не успели завершить свою миграцию с железа на виртуализацию, как появились контейнеры.
Отучиться чему-то очень сложно, Большинство людей, начиная использовать контейнеры, рассматривают их вначале лишь как еще один уровень абстракции над уже имеющимися у них практиками и привычками:
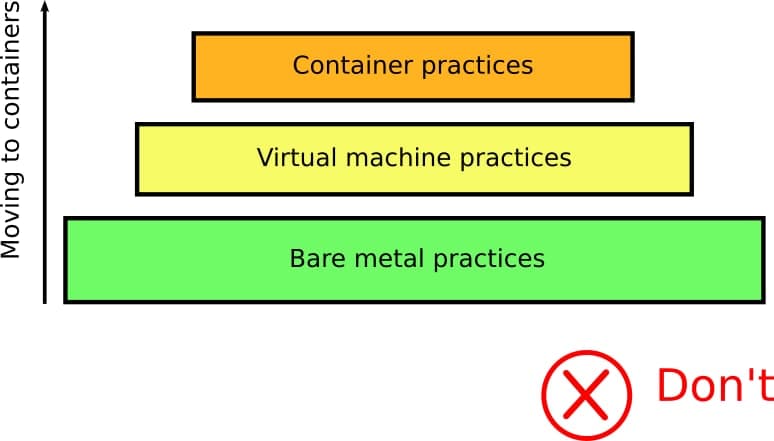
В реальности де, контейнеры требуют абсолютно иных взглядов и подхода, а так же изменения существующих процессов. Вам необходимо переосмыслить ВСЕ ваши процессы CI/CD и адаптировать их для контейнеров.
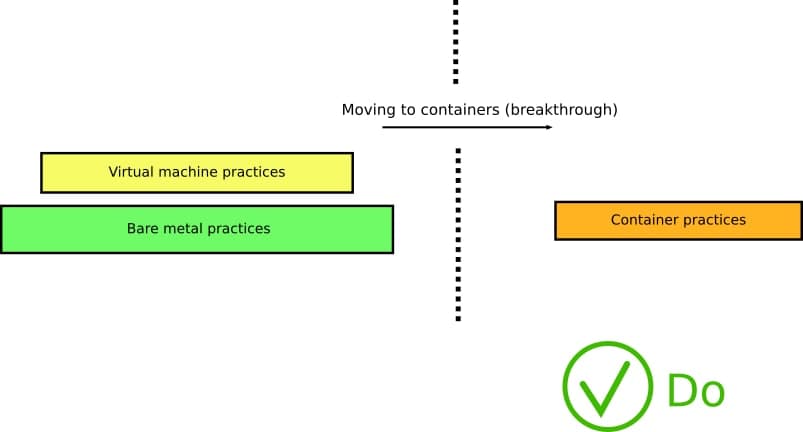
К несчастью нет простого пути исправить все эти анти-паттерны иначе как изучить природу контейнеров, строительные блоки из которых состоит эта технология и их историю (возвращаясь к тем временам, когда наши бородатые предки еще использовали chroot — господи, кто нибудь еще помнит это?).
Если вы регулярно замечаете себя за открыванием ssh сессий к запущенным контейнерам для того чтобы “обновить” их, или вручную вытаскиваете из них файлы/логи, вы точно пошли не тем путем в использовании Docker и вам вначале нужно потратить время и почитать как работают контейнеры.
Проблема XY — коммуникационная проблема, возникающая в службе технической поддержке и аналогичных ситуациях, когда просьбе о помощи скрывает реальную проблему X потому что вместо того чтобы спросить про X, спрашивают как решить вторичную проблему Y, свято считая что это позволит им решить изначальную проблему X. Однако зачастую решение Y не проводит к решению X, либо является плохим способом решения, в то время как введение вторичной ложной проблемы Y отнимает силы и время у помогающего, также вводя его в заблуждение. Об этой проблеме не плохо написано на хабре в блоге инжениринга ребят из DoDO.
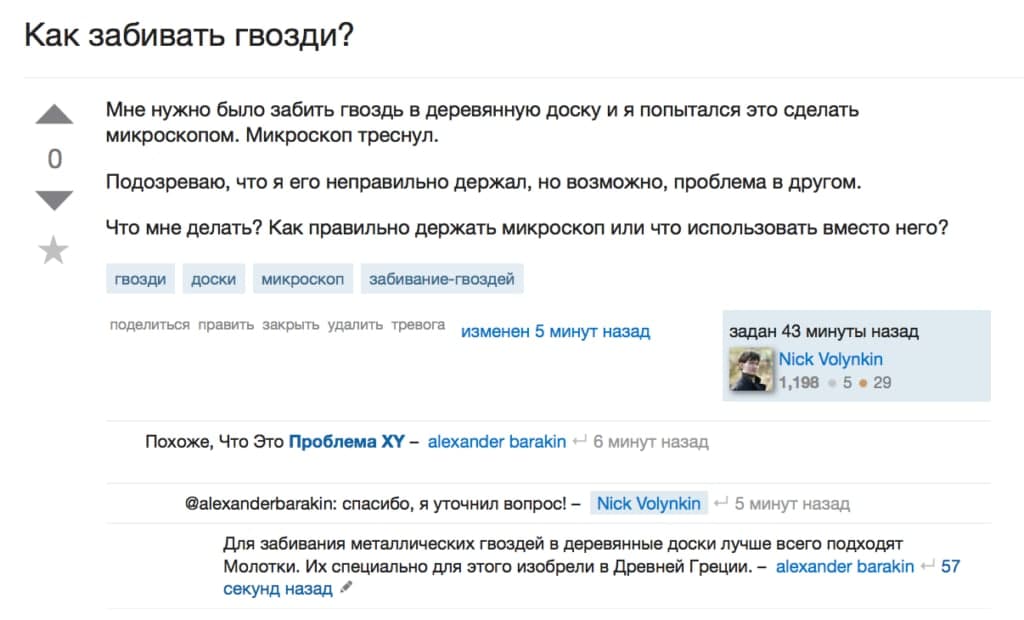
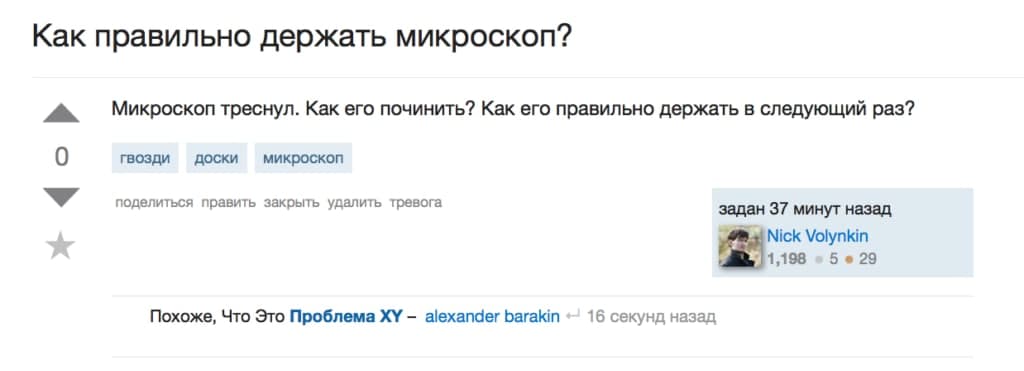
Ярким шуточным примером может служить проблема микроскопа:
Ярким шуточным примером проблемы XY может служить «проблема микроскопа», которая формулируется вот таким образом.
Более жизненный пример:
АААА: Как мне вывести последние три символа файла?
ВВВВ: Ну, например, так: echo ${foo: -3}
ВВВВ: А зачем три символа? Что надо-то?
ВВВВ: Может, расширение файла?
АААА: Да.
ВВВВ: Так и говори прямо, чего хочешь!
ВВВВ: Не факт, что каждое имя файла имеет трехбуквенное расширение.
ВВВВ: Так что тупо взять три последних символа — это не решение проблемы.
ВВВВ: Нужно так: echo ${foo##*.}
Чтобы избежать проблемы XY, стоит придерживаться следующих несложных правил:
- Предоставлять достаточно широкую информацию о решаемом вопросе — кроме самого неудачного примера стоит написать, чего вы хотите добиться в целом;
- Если кто-то просит у вас больше информации о проблеме, вероятно, стоит эту информацию предоставить;
- Всегда пишите о том, что вы уже пробовали делать и почему от этого отказались. Это поможет точнее определить, что именно вам необходимо.
И помните: если бы ваши догадки всегда оказывались верными, вам бы не нужна была помощь, верно?
Антипаттерн намбер ту
Создание “не прозрачных”, запутанных/неочевидных Docker файлов и образов
Dockerfile должен иметь прозрачную конфигурацию, желательно заключенную только в нем самом (без ссылок на какие-либо внешние конфигурационные зависимости).
Он должен так или иначе описывать все компоненты приложения в явном виде (если вам что то нужно установить — делайте это явно). Он должен быть таким, что взяв ваш Dockerfile кто угодно должен получить такой же результат (образ).
Приемлемым считается ситуация, когда в нем содержатся инструкции по загрузке дополнительных библиотек и пакетов (правда с явным указанием версий, чтобы это было легко контролировать), одно стоит избегать Dockerfiles у которых под капотом происходит какая то магия.
Вот плохой пример:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
FROM alpine:3.4 RUN apk add --no-cache \ ca-certificates \ pciutils \ ruby \ ruby-irb \ ruby-rdoc \ && \ echo http://dl-4.alpinelinux.org/alpine/edge/community/ >> /etc/apk/repositories && \ apk add --no-cache shadow && \ gem install puppet:"5.5.1" facter:"2.5.1" && \ /usr/bin/puppet module install puppetlabs-apk # Install Java application RUN /usr/bin/puppet agent --onetime --no-daemonize ENTRYPOINT ["java","-jar","/app/spring-boot-application.jar"] FROM alpine:3.4 RUN apk add --no-cache \ ca-certificates \ pciutils \ ruby \ ruby-irb \ ruby-rdoc \ && \ echo http://dl-4.alpinelinux.org/alpine/edge/community/ >> /etc/apk/repositories && \ apk add --no-cache shadow && \ gem install puppet:"5.5.1" facter:"2.5.1" && \ /usr/bin/puppet module install puppetlabs-apk # Install Java application RUN /usr/bin/puppet agent --onetime --no-daemonize ENTRYPOINT ["java","-jar","/app/spring-boot-application.jar"] |
Не поймите меня неправильно, я люблю Puppet (автор, не я) и это отличный инструмент (или Ansible, или Chef, не важно). Однако если не очень аккуратное его использование для VM еще не так страшно, для контейнеров это катастрофа!
Во первых, это делает наш Dockerfile зависимым от локации. Скажем вы испытали его на машине, имеющей доступ к Puppet серверу. Ваша собственная машина будет иметь доступ к этому серверу? А ваша продакшен среда? Или вы имеете доступ к прод puppet серверу? А должны ли вы иметь к нему доступ? (Ну и все такое)
Но самое страшное, что такой образ не может быть легко воспроизведен. Содержимое будет зависеть от того, к какому серверу мы обращаемся на этапе сборке образа. Получив сегодня одно, завтра вы можете получить совсем нечто, сильно отличающееся. А если у вас нет доступа к Puppet серверу или он сейчас не работает, вы просто не сможете ничего собрать. Вы также никогда не узнаете, какие версии приложений будут установлены, если у вас нет доступа к сценариям puppet.
Команда, сотворившая этот Dockefile просто состоит из лентяев. У низ был скрипт puppet для установки приложения на виртуальную машину и они просто решили переиспользовать его для Dockerfile, тем самым тригернув прошлый антипаттерн.
Исправить ситуацию в данном случае можно использованием минималистичного Dockerfile, который бы явно описывал то, что делается. Вот то же самое приложение и “правильный” Dockerfile:
|
1 2 3 4 5 6 7 8 9 10 11 |
FROM openjdk:8-jdk-alpine ENV MY_APP_VERSION="3.2" RUN apk add --no-cache \ ca-certificates WORKDIR /app ADD http://artifactory.mycompany.com/releases/${MY_APP_VERSION}/spring-boot-application.jar . ENTRYPOINT ["java","-jar","/app/spring-boot-application.jar"] |
Стоит отметить что:
- нет более никаких зависимостей от инфраструктуры puppet. Dockerfile может быть использован на рабочем месте любого разработчика, у которого есть доступ к репозиторию
- Явно обозначены версии приложений
- Мы можем легко изменить версию приложения простым редактированием только Dockerfile (вместо того чтобы править скрипты puppet).
Это очень простой и надуманный пример. Я (автор оригинальной статьи) видел не мало Dockerfile которые зависели от “магических” рецептов с специальными требованиями -где и как они должны быть собраны. Не повторяйте эти ошибки, ведь в таком случае разработчики (и любые другие люди, кто не имеет доступа ко всем системам), получат лишние сложности по сборке Docker образов локально на их машинах.
Еще лучшей альтернативой будет Dockerfile, который комплиирует исхдный код java в процесе сборки образа самостоятельно (используется стратегия multi-stage builds — я намеренно это не перевожу чтобы было проще найти в документации ). Это даст вам больше понимания что де происходит в вашем образе Docker.
Антипаттерн номер три
Создание Dockerfile-ов которые могут как то влиять на внешнее окружение
Давайте представим что вы оператор или SRE работающий в большой компании (ха ха, мне даж представлять не нужно), в которой используется множество языков программирования (ну и разных окружений). Стать экспертом во всем этом — весьма трудная задача.
Это одно из главных преимуществ контейнеров в первую очередь. Вам необходимо иметь возможность скачать любой Dockerfile от любой команды разработки и собрать на его основе образ, не беспокоясь ни о каких побочных эффектах (потому что их не должно быть).
Сборка образа Docker должна быть идемпотентной операцией. Не должно иметь значения — собираете вы этот образ единожды или 100500 раз. Или то что вы собираете его на CI сервере или на своем рабочем месте.
Есть несколько примеров создания Dockerfiles которые нарушают это:
- выполнение git commits или других активных действий с git (имеется в виду когда мы работаем не в формате read only)
- очищаем или как то видоизменяем данные в БД
- вызываем внешние сервисы используя операции POST/PUT (то есть не скачиваем а наоборот, загружаем туда что-то)
Вот вам простой пример, когда в Dockerfile одновременно присутсвуют оба случая — упаковка (безопасное действие) и публикация ( не безопасное действие) приложения через npm (nodejs) при запуске:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
FROM node:9 WORKDIR /app COPY package.json ./package.json COPY package-lock.json ./package-lock.json RUN npm install COPY . . RUN npm test ARG npm_token RUN echo "//registry.npmjs.org/:_authToken=${npm_token}" > .npmrc RUN npm publish --access public EXPOSE 8080 CMD [ "npm", "start" ] |
В данном случае смешали два понятия — выпуск новой версии приложения и создание Docker образа для него. Да, возможно эти вещи должны происходит единомоментно в некоторых случаях (но почему бы не по очереди?), однако это не повод оправдывать загаживание Dockerfile подобными эффектами.
Docker — не универсальная CI система и не должна быть ей. Не злоупотребляйте Dockefile, используя их на замену православным bash скриптам, обладающим неограниченной мощью. Наличие побочных эффектов во время работы контейнера — это нормально, а вот во время сборки — нет (в первом случае у вас уже работает экземпляр приложения внутри контейнера и работа приложения связана с созданием побочных эффектов — оно что то делает в базе, оно создает или передает файловые объекты и тп. Во втором же случае мы лишь собираем приложение в готовый к запуску артефакт).
Решением является упрощение Dockerfile и проверка того что он теперь включает в себя только идемпотентные операции, такие как:
- клонирование исходного кода
- скачивание зависимостей
- компиляция или упаковка исходного кода
- обработка-минимизация-преобразование локальных ресурсов
- запуск скриптов и редактирование файлов, лежащих только в файловой системе контейнера.
Так же держите в голове факт того что Docker кеширует слои файловой системы. То есть он ожидает что если какой то слой (в образе контейнера) и те что были до него не изменились, они могут быть повторно использованы из кеша. Если ваши операции в Dockerfiles имеют внешние побочные эффекты, они не учитывают эту и нарушают эту концепцию (результат как мы понимаем может быть непредсказуемым).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
FROM node:10.15-jessie RUN apt-get update && apt-get install -y mysql-client && rm -rf /var/lib/apt RUN mysql -u root --password="" < test/prepare-db-for-tests.sql WORKDIR /app COPY package.json ./package.json COPY package-lock.json ./package-lock.json RUN npm install COPY . . RUN npm integration-test EXPOSE 8080 CMD [ "npm", "start" ] |
Давайте предположим что вы попытались собрать образ из этого файла и ваши unit тесты упали с ошибкой. Вы вносите правку в исходный код и пробуете пересобрать это все снова. Докер будет ожидать что слой, содержащий команду очистки БД у вас уже отрабатывал, не изменился и он может переиспользовать “кеш”. Поздравляю — ваши unit тесты запущены в среде, в которой не была произведена очистка БД, которая содержит данные с предыдущего прогона тестов.
В этом выдуманном примере к нашему счастью Dockerfile еще крайне мал и мы легко можем обнаружить команду, которая имеет побочные эффекты для внешней среды, чтобы внести правки и исключить эту ситуацию, однако в жизни у вас могут быть очень большие Dockerfiles и вам будет очень трудно раскопать — какие же команды и операции имеют внешние эффекты, а какие нет.
Антипаттерн номер четыре
Смешивать и путать образы используемые для разработки, с образами для развертывания
В большинстве компаний, взявших контейнеры на вооружение существует две различные категории Docker образов.
Первая включает в себя образы, непосредственно используемые как артефакты для развертывания приложения на продакшен сервера.
Они должны включать:
- Код приложения в упакованном или скомпилированном виде плюс runtime (среда исполнения — JRE для java приложений, php-fpm для приложений на php и тп) и все зависимости
- Ничего больше. реально ничего.
Вторая категория это образы, используемые для CI/CD систем или разработчиками. Они могут включать в себя:
- Оригинальный исходный код — не упакованный, не скомпилированный
- Компиляторы, упаковщики, трансляторы
- Тестовые фреймворки и утилиты для генерации отчетов
- Статические анализаторы, сканеры безопасности, сканеры качества кода
- инструменты интеграции с облаками
- любые другие инструменты которые могут быть полезны для CI/CD конвейеров
Кажется очевидным, что обе категории должны существовать отдельно (создаваться, храниться, управляться, использоваться) потому что они существуют для разных задач и служат разным целям. Образы, которые разворачиваются на продакшен серверах должны быть минималистичными, безопасными и проверенными (тут автор использует термин “закаленные в боях” — я думаю речь идет о тестировании со всех сторон).
Образы, которые используются в процессе CI/CD и никогда не развертываются ни на какие среды, могут не отвечать таким строгим требованиям — к ним применимы послабления.
Однако почему то не все понимают такое различие. Я (автор оригинала) видел несколько компаний, которые пытались использовать один и тот же образ как для разработки так и для развертывания. В итоге это приводит к тому что в рабочем образе, используемом для запуска приложения на продакшене находятся ненужные утилиты и фреймворки.
Существует ровно 0 (ноль) причин, по которым образ используемый на продакшене для работы приложения должен содержать git, тестовые фреймворки или компиляторы.
Да, контейнеры являются универсальными артефактами развертывания, что означает что один и тот же артефакт будет использоваться в различных средах, чтобы убедиться в том что то что вы развернули — это то же самое что вы ранее тестировали. Однако попытка объединить локальное развертывания (с целями разработки) вместе с продакшн развертыванием — это заранее проигранная битва.
Таким образом, попытайтесь понять какую роль исполняет тот или иной образ Docker. У каждого из них должна быть своя роль. Если вы отправляете в продакшен фреймворк для тестирования, вы совершаете ошибку. Возможно вам лучше притормозить и потратить время на изучение multi-stage сборок.
Пятый антипаттерн
Использование разных образов для каждого окружения(контура, как некоторые их зовут) — QA, Stage, Prod.
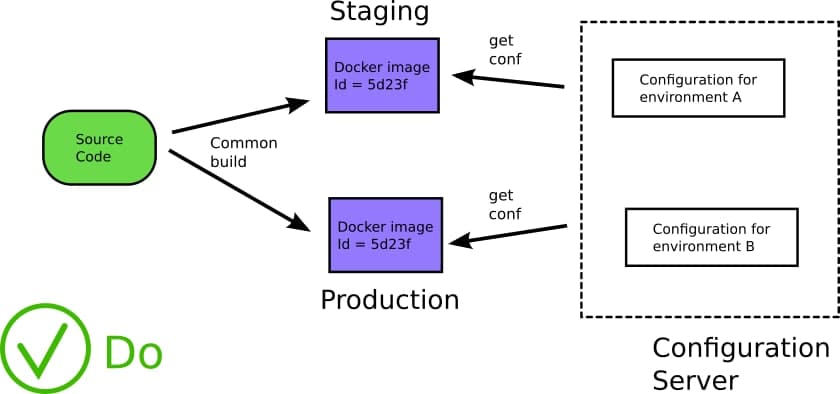
Одно из главных и очень важных преимуществ, которые дают контейнеры — их иммутабельность (грубо говоря — неизменность. То есть будучи единожды созданный — образ у вас не будет изменяться. при внесении изменений и коммите — вы получите новый образ но все щее сможете воспользоваться старым). Это означает что Docker образ должен создаваться только один раз а после этого — поставляться в различные окружения до тех пор, пока не достигнет продакшена.
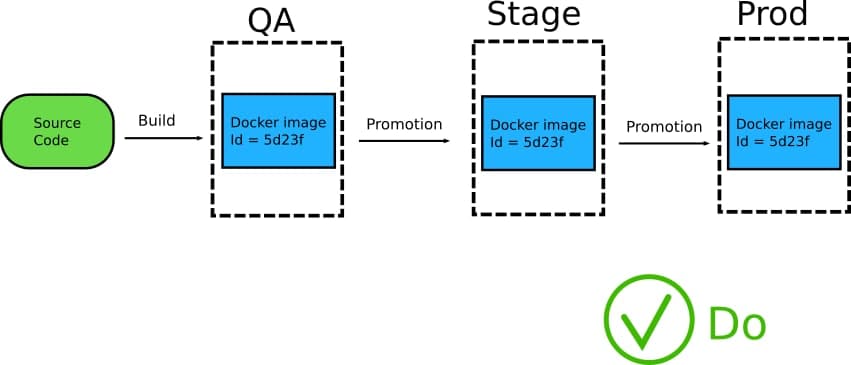
В силу того что тот же образ поставляется как единая сущность, вы получаете гарантию, что то что вы ранее тестировали- вы и получите на каждом из окружений.
Я (автор оригинала) видел не мало компаний, создающих различные артефакты для их окружений, с немного другими версиями кода и конфигурацией (тут имеется ввиду скорее всего не настройка самого приложения а вещи, имеющие больше отношения к коду, например параметры сборки).
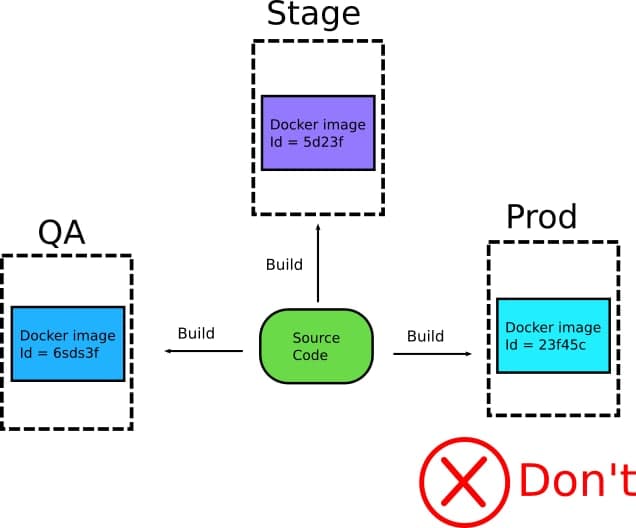
Собственно в этом случае вы сами создаете себе проблему, так как нет гарантии того что образы достаточно единообразны чтобы иметь впоследствии одинаковое поведение. Еще больше усугубляет ситуацию то что разработчики или инженеры эксплуатации запихивают в образ дополнительные отладочные инструменты в “не продакшен” образы, тем самым еще больше усиливая разрыв между образам.
Вместо того чтобы пытаться понять что различные образы внутри себя хоть сколько нибудь похожи (что на прод к вам поступило именно то, что проверяли QA), проще (и правильнее) использовать единые образ на всех этапах жизни программного продукта.
Запомните — это нормально что различные окружения (контуры) используют разные настройки (секреты, конфигурационные переменные). Далее мы еще поговорим об этом. Все прочее же должно быть идентичным.
Шестой антипаттерн
Создание Docker образов на продакшен серверах.
Docker реестр содержит каталог уже существующих приложений, которые могут быть пере развернуты в любое время на любом окружении. Это так же центральное место хранение дополнительных компонентов приложений и метаданных, включая историю предыдущих версий того же самого приложения. Достаточно просто выбрать специфичный тег, обозначающий тот или иной образ и развернуть его в любом окружении
Один из наиболее гибких путей использования реестра Docker это перемещение образов между ними. У организации должно быть как минимум два реестра (один для разработки и второй для продакшена). Образ собирается единожды и помещается в реестр разработки. дальше, после проведения интеграционного тестирования, секьюрити сканирования и других проверок, образ может быть перемещен в продакшен реестр, чтобы в далее развернуть его на серверах в проде или в кубер кластере.
Также, возможно иметь различные реестры — например для каждого региона-локации или для каждого департамента. Основная мысль тут в том что каноничный путь эксплуатации Docker включает в себя правильную эксплуатацию реестра. Реестры Docker служат как хранилищем ресурсов приложений, так и промежуточным хранилищем перед развертыванием приложения в рабочей среде.
Крайне странной является практика полного изъятия реестров из жизненного цикла приложения, с последующим запихиванием исходного кода приложения напрямую на продакшен сервера.
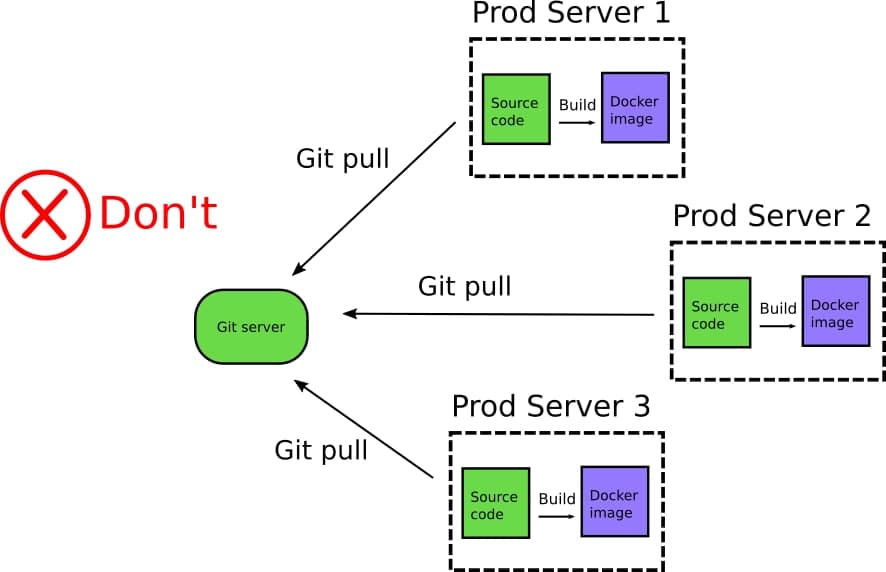
Продакшен сервер выполняет “git pull” чтобы скачать исходный код приложения и далее “docker build” чтобы собрать образ на лету и сразу локально запустить его (обычно используют для этого Docker Compose или какую другую кастомную оркестрацию). Этот “способ развертывания” сразу несет в себе пачку антипаттернов за раз!
Эта практика развертывания уязвима перед целым ворохом проблем, включая проблемы безопасности. Продакшен сервера не должны иметь доступа к вашим git репозиториям. Если компания заботится о своей безопасности. Этот антипаттерн у нас не пройдет уже как минимум по требованиям безопасности (я бы сказал по здравому смыслу). Сложно найти причину почему вообще git должен установлен на продакшен сервера. Git (или любая другая система контроля версий) это инструмент созданный для совместной работы разработчиков а не как решение для доставки артефактов.
Но куда страшнее то что с этим “методом развертывания”, вы больше не знаете какой образ развернут на каком из серверов (и что там вообще в итоге получилось), так как у вас больше нет центрального места хранения образов.
Короче говоря этот метод может работать для стартапов но очень быстро покажет свою неэффективность в больших инсталляциях. Вам необходимо изучить как использовать реестры Docker и какие еще преимущества они несут вам (в том числе возможность производить сканирование безопасности образов контейнеров).
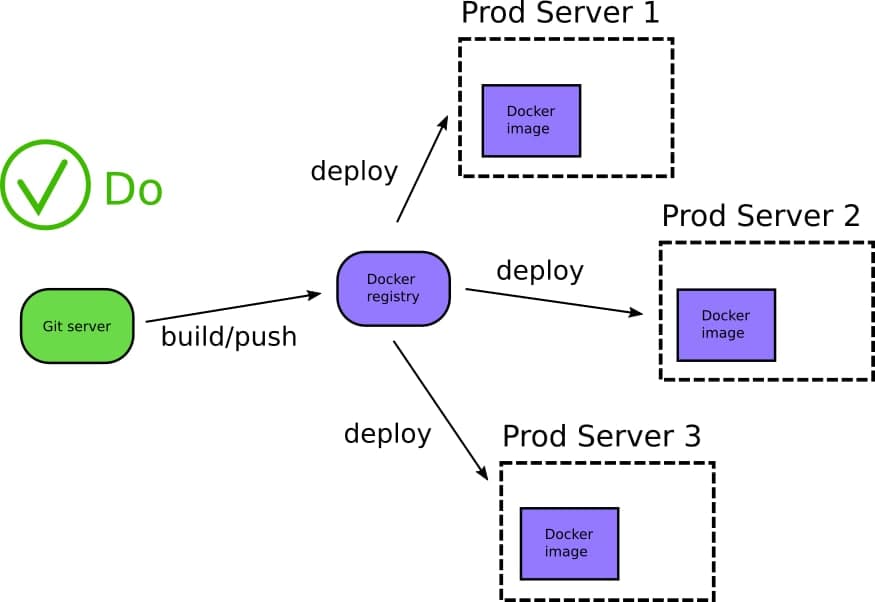
Реестры Docker имеют отлично определенный API и на рынке уже есть не было открытых и проприетарных продуктов которые могут быть использованы вами чтобы развернуть подобный реестр внутри вашей организации.
Обратите внимание также на то, что с помощью реестров Docker ваш исходный код надежно находится за фаерволом вашего внутреннего закрытого контура и никогда не покидает его.
Седьмой антипаттерн
Работа со значениями git hash вместо образов Docker
В качестве следствия устранения двух предыдущих антипаттернов, является то, что как только вы начинаете эксплуатацию контейнеров, реестр Docker должен незамедлительно стать единственным источником истины и отправной точкой для любой дальнейшей активности (тестирования, развертывания и пр. Написали код, собрали образ, запихали в реестр. Все остальное — после).

Это сразу вступает в контры с одним из старых способов, когда в качестве основных артефактов продвижения наработок на тестирование и в прод выступали значения git-hash. Исходный код беспорно необычайно важен однако пересоздание (докер образа) из одного и того же git-hash(то есть на основании одного и того же коммита) раз за разом, с последующим его продвижением в тестовую среду и в прод — это пустая трата времени и сил. Некоторые компании (опять же это мнение автора оригинала) считают, что контейнеры — это сущность которая должна быть сугубо в ведении отдела эксплуатации (operations), в то время как разработчики работают только с исходным кодом. Это слишком “хорошо” чтобы быть правдой (в смысле это ужасная идеология, которая как раз и возводит стену dev-ops, которую пытается сломать идеология DevOps). Технология контейнеризации это прекрасный повод и способ разработчикам и эксплуатации поработать рука об руку.

В идеале, ребята из отдела эксплуатации больше не должны переживать о том, что происходит с git репозиторием приложения (и в нем). Все что им нужно знать — это готов ли образ Docker, есть ли он у них под рукой (в доступном реестре) и можно ли его катить на прод.
Спросите отдел эксплуатации в вашей организации- не стали вы как компания жертвой этого антипатерна. Если они вынуждены вникать в тонкости внутренних компонентов приложения, такими как системы сборки (тут имеется ввиду на Ci/CD системы типа Gitlab CI или jenkins, а скорее npm, maven, gcc и тп) или тестовые фреймворки — то есть в сущности, никак не связанные с средой выполнения приложения, это означает, что они испытывают повышенную когнитивную нагрузку, которая на самом деле не нужна в ежедневные задачах, решаемых отделом эксплуатации.
Тут я на самом деле несколько не соглашусь с автором оригинала. Если мы говорим про совместную работу отдела разработки и отдела эксплуатации, зачастую ops-ы помогают dev-ам развернуть и поддерживать и все то, что касается сборки, и тестирования и тп. И зачастую я не вижу ничего плохого в том, чтобы вникнуть и в сборку и в тестирование. Но вникнуть от слова “чуть чуть”. А не так что при каждом падении maven, dev делал бы лапки кверху и пинал бы ops-а у которого параллельно на проде что-то полыхает (возможно пониже спины, как раз из за того, что в прошлый раз собрали dev-ы).
Восьмой антипаттерн
Жесткое встраивание секретов и конфигурации в образ контейнера
Этот антипаттерн сильно связан с 5-ым антипаттерном, приведенным ранее (различные образы под разные окружения). В большинстве случаев когда я (автор оригинала) спрашиваю компании, почему им нужны разные образы для разных окружений (qa/stage/prod), обычно слышу в ответ что они включают в себя разные конфигурационные значения и секреты.
Это опять же, ломает не только основную концепцию Docker — “деплой то что тестировал” но так же сильно усложняет CI/CD пайплайны (для сборки и деплоя), вынуждая встраивать в них управления секретами и конфигурацией во время создания образов.
Антипаттерн заключается в основном в жестком встраивании конфигурации (да,да, “мягкого встраивания нет” — я честно не знаю как адекватно перевести термин “hardcode” — я даже по русски так говорю. Имхо наиболее подходящая альтернатива, которая отражает смысл это “вкрячивать”). Приложение не должно иметь встроенной конфигурации. Правда это не должно быть сюрпризом для тех, кто знаком с идеей 12 факторного приложения (еще так же известно как 12 факторов облачного приложения)
Ваши приложения должны подтягивать конфигурацию во время запуска и выполнения, а не во время сборки. Образ докера должен быть конфигурационно независимым. Только во время запуска, конфигурация должна “прицепляться” к контейнеру. И сейчас есть куча решений для этого и большинство систем кластеризации и развертывания могут работать с решениями для загрузки конфигурации при старте (configmaps, zookeeper, consul, etc) и секреты (vault, keywhiz, confidant, cerberus).
Если же ваш образ Docker включает жестко заданные IP адреса (не для себя а как ссылки на другие ресурсы типа адрес БД) или параметры доступа к чему то (ключи, логины-пароли, токены), вы точно делаете что то не так.
Девятый антипаттерн
Создание Docke файлов которые дофига чего делают
Мне (автору оригинала) доводилось сталкиваться со статьями (хоть одну показал бы. шутка) в которых описывалось что Dockerfile может быть использован как CI решение для бедных (или как упрощенный CI).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Run Sonar analysis FROM newtmitch/sonar-scanner AS sonar COPY src src RUN sonar-scanner # Build application FROM node:11 AS build WORKDIR /usr/src/app COPY . . RUN yarn install \ yarn run lint \ yarn run build \ yarn run generate-docs LABEL stage=build # Run unit test FROM build AS unit-tests RUN yarn run unit-tests LABEL stage=unit-tests # Push docs to S3 FROM containerlabs/aws-sdk AS push-docs ARG push-docs=false COPY --from=build docs docs RUN [[ "$push-docs" == true ]] && aws s3 cp -r docs s3://my-docs-bucket/ # Build final app FROM node:11-slim EXPOSE 8080 WORKDIR /usr/src/app COPY --from=build /usr/src/app/node_modules node_modules COPY --from=build /usr/src/app/dist dist USER node CMD ["node", "./dist/server/index.js"] |
Хоть на первый взгляд этот Dockerfile и может показаться неплохим примером мульти ступенчатой сборки, однако по факту он представляет собой сплав антипаттернов:
- он предполагает наличие серверов SonarQube (второй антипаттерн)
- он воздействует на окружающую среду за счет отправка артефактов в S3 (третий антипаттерн)
- Он работает как образ и для разработки и для развертывания (антипаттерн 4)
Docker не является сам по себе CI системой. Технология контейнеризации может быть использована как часть CI/CD конвеера однако технически это совсем другая сущность. Не стоит путать команды необходимые для запуска Docker контейнера, с командами которые необходимы для запуска задач сборки в рамках CI.
Автор вот этого Dockerfile выступает за то, чтобы использовать параметры сборки, взаимодействующие с метками внутри Dockerfile (лейблами — labels) для того чтобы включать-выключать те или иные этапы сборки (например отключение sonar). Выглядит как добавление геморроя ради удовлетворения чсв (в оригинале “сложность ради усложнения” но кмк мой перевод более точен).
Исправить этот Dockerfile можно просто разбив его на отдельные 5 файлов. Один- для развертывания приложения и все прочие для других шагов в рамках вашего CI/CD конвейера. Один Dockerfile должен решать одну задачу.
Десятый антипаттерн
Создание Docke файлов делают слишком мало
В силу того что контейнеры также включают и все свои зависимости, они являют собой отличное решение для изоляции библиотек и фреймворков соответствующих версий для ваших приложений. Разработчикам знакомы ситуации, когда они пытаются установить несколько различных версий одного и того же инструмента на свой рабочий компьютер. Docker позволяет решить эту проблему, за счет описания того, что именно нужно вашему приложению, размещая это описание в соответствующем Dockerfile.
Однако это справедливо лишь в том случае, если вы со своей стороны следуете концепции. Инженер эксплуатации не должен заботиться о том, как и какой программный инструмент вы используете в своем образе. Он должен иметь возможность создать образ докера для Java приложения, потом для Python и затем для NodeJS, не имея по факту никаких средств разработки установленных на его ноутбуке.
Многие компании (а список он так и не приводит) по прежнему рассматривают Docker чисто как формат упаковки и просто используют его для того чтобы упаковывать свои приложения, созданные вне контейнера. Этот антипаттерн особенно ярко проявляется в среде серьезных (в оригинале было “тяжелых” но я думаю что речь идет про тру-энтерпрайз) Java приложений и даже официальная документация грешит этим.
Вот пример Dockerfile предлагаемого в официальной документации Spring Boot Docker guide.
|
1 2 3 4 5 |
FROM openjdk:8-jdk-alpine VOLUME /tmp ARG JAR_FILE COPY ${JAR_FILE} app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
Этот Dockerfile чисто упаковывает уже существующий jar файл. Как он был создан? Никто не знает. Это не описано в Dockerfile. Оператор вынужден будет отдельно устанавливать Java библиотеки только для того чтобы собрать этот jar и потом собрать образ из этого Dockerfile. Если же вы работаете в организации, в которой используется несколько языков, процесс быстро выйдет из под контроля и вы получите ад и содомию (хаос и ад зависимостей и конфликтов) на рабочих местах операторов и на сборочных хостах.
Java десь была использована только для примере, однако этот антипаттерн можно легко встретить и в других ситуациях. Например Dockerfile не будет работать для вас, пока вы не выполните локально “npm install”. И это достаточно распространенное явление.
Решение этого анти паттерна ровно такое же как для анти паттерна номер два. Просто убедитесь что ваш Dockerfile содержит полное описание процесса. Ваши инженеры эксплуатации будут любить вас еще больше, если в будете следовать этому подходу. Ниже пример, как можно модифицировать этот же Dockerfile чтобы он следовал этому походу:
|
1 2 3 4 5 6 7 |
FROM openjdk:8-jdk-alpine COPY pom.xml /tmp/ COPY src /tmp/src/ WORKDIR /tmp/ RUN ./gradlew build COPY /tmp/build/app.war /app.jar ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"] |
В данном случае Dockerfile точно описыва как приложение было создано и он может быть использован кем угодно, на любом рабочем месте без необходимости устанавливать себе среду разработки java. В будущем этот файл можно улучшить, например с помощью мульти-этапной сборки.
Заключение
Многие компании испытывают проблемы при адаптации контейнеров, из за того что они пытаются практики свои практики для VM на контейнеры. Лучше потратить некоторое время на то, чтобы переосмыслить все преимущества, которыми обладают контейнеры, и понять, как вы можете создать свой процесс с нуля с помощью этих новых знаний.
В этом руководстве я (автор) представил несколько плохих практик использования контейнеров, а также решение каждой из них.
- Попытка использовать методы виртуальной машины на контейнерах. Решение: понять, что такое контейнеры.
- Создание непрозрачных файлов Docker. Решение: напишите Dockerfiles с нуля вместо того, чтобы использовать существующие скрипты.
- Создание Dockerfiles, которые как то влияют на внешнее окружение. Решение: переместите это влияние в ваше решение CI/CD и получите Dockerfiles без него.
- Путать образы, используемые для развертывания, с образами, используемыми для разработки. Решение: не отправляйте инструменты разработки и тестовые фреймворки на производственные серверы.
- Создание различных образов для каждой среды. Решение: создайте образ только один раз и продвигайте его в различных средах
- Вытягивание кода с производственных серверов и создание образов на лету. Решение: используйте реестр Docker
- Продвижение git-хэшей между командами. Решение: продвижение образов контейнеров между командами
- Закапывание секретов в образах. Решение: создайте образ только один раз и используйте подключаемую конфигурацию в среде выполнения
- Использование Docker в качестве CI/CD. Решение: используйте Docker в качестве артефакта развертывания и выберите решение CI/CD для CI/CD
- Предполагая, что контейнеры-это тупой метод упаковки. Решение: Создайте Dockerfiles, которые компилируют/упаковывают исходный код самостоятельно с нуля.
- Посмотрите на свои рабочие процессы, спросите разработчиков (если вы оператор) или операторов (если вы разработчик) и попытайтесь найти, попадает ли ваша компания в одну или несколько из этих плохих практик.
Знаете ли вы о каких-либо других хороших/плохих контейнерных практиках?